NOTE:文章在SegmentFault同步更新 http://segmentfault.com/blog/eric/1190000002544142
上回,我装了环境
也就是一对乱七八糟的东西
装了pip,用pip装了virtualenv,建立了一个virtualenv,在这个virtualenv里面,装了Django,创建了一个Django项目,在这个Django项目里面创建了一个叫做web的阿皮皮。
接上回~
第二部分,编写爬虫。
工欲善其事,必先利其器。
apt-get install vim
当然了,现在我要想一个采集的目标,为了方便,我就选择segmentfault吧,这网站写博客不错,就是在海外上传图片有点慢。
这个爬虫,就像我访问一样,要分步骤来。 我先看到segmentfault首页,然后发现里面有很多tags,每个tags下面,才是一个一个的问题的内容。
所以,爬虫也要分为这几个步骤来写。 但是我要反着写,先写内容爬虫,再写分类爬虫, 因为我想。
2.1 编写内容爬虫
首先,给爬虫建立个目录,在项目里面和app同级,然后把这个目录变成一个python的package
mkdir ~/python_spider/sfspider
touch ~/python_spider/sfspider/__init__.py
以后,这个目录就叫爬虫包了
在爬虫包里面建立一个spider.py用来装我的爬虫们
vim ~/python_spider/sfspider/spider.py
一个基本的爬虫,只需要下面几行代码:
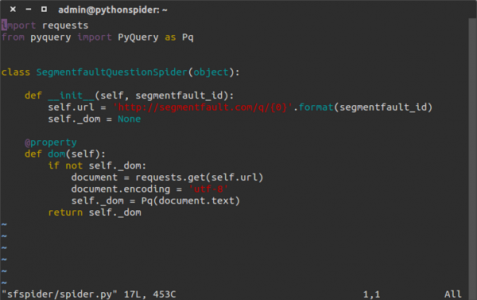
(代码下面会提供)
然后呢,就可以玩玩我们的“爬虫”了。
进入python shell
>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> s.url
>>> 'http://segmentfault.com/q/1010000002542775'
>>> print s.dom('h1#questionTitle').text()
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
看吧,我现在已经可以通过爬虫获取segmentfault的提问标题了。下一步,为了简化代码,我把标题,回答等等的属性都写为这个蜘蛛的属性。代码如下
import requests
from pyquery import PyQuery as Pq
class SegmentfaultQuestionSpider(object):
def __init__(self, segmentfault_id):
self.url = 'http://segmentfault.com/q/{0}'.format(segmentfault_id)
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
return self._dom
@property
def title(self):
return self.dom('h1#questionTitle').text()
@property
def content(self):
return self.dom('.question.fmt').html()
@property
def answers(self):
return list(answer.html() for answer in self.dom('.answer.fmt').items())
@property
def tags(self):
return self.dom('ul.taglist--inline > li').text().split()
然后,再把玩一下升级后的蜘蛛。
>>> from sfspider import spider
>>> s = spider.SegmentfaultQuestionSpider('1010000002542775')
>>> print s.title
>>> 微信JS—SDK嵌套选择图片和上传图片接口,实现一键上传图片,遇到问题
>>> print s.content
>>>
>>> for answer in s.answers
print answer
>>>
>>> print '/'.join(s.tags)
>>> 微信js-sdk/python/微信开发/javascript
OK,现在我的蜘蛛玩起来更方便了。
2.2 编写分类爬虫
下面,我要写一个抓取标签页面的问题的爬虫。
代码如下, 注意下面的代码是添加在已有代码下面的, 和之前的最后一行之间 要有两个空行
class SegmentfaultTagSpider(object):
def __init__(self, tag_name, page=1):
self.url = 'http://segmentfault.com/t/%s?type=newest&page=%s' % (tag_name, page)
self.tag_name = tag_name
self.page = page
self._dom = None
@property
def dom(self):
if not self._dom:
document = requests.get(self.url)
document.encoding = 'utf-8'
self._dom = Pq(document.text)
self._dom.make_links_absolute(base_url="http://segmentfault.com/")
return self._dom
@property
def questions(self):
return [question.attr('href') for question in self.dom('h2.title > a').items()]
@property
def has_next_page(self):
return bool(self.dom('ul.pagination > li.next'))
def next_page(self):
if self.has_next_page:
self.__init__(tag_name=self.tag_name ,page=self.page+1)
else:
return None
现在可以两个蜘蛛一起把玩了,就不贴出详细把玩过程了。。。
>>> from sfspider import spider
>>> s = spider.SegmentfaultTagSpider('微信')
>>> question1 = s.questions[0]
>>> question_spider = spider.SegmentfaultQuestionSpider(question1.split('/')[-1])
>>>
想做小偷站的,看到这里基本上就能搞出来了。 套个模板 加一个简单的脚本来接受和返回请求就行了。
未完待续。
下一篇,采集入库!